Abstract
We studied the Cumulative Spectral Gradient (CSG) — a metric proposed to measure image dataset complexity — to see whether it really tells you how hard a knowledge-graph link-prediction problem is. By running careful experiments on common benchmarks (e.g., FB15k-237, WN18RR) we found that CSG’s values strongly depend on how the metric is computed (especially the nearest-neighbour parameter (K)), and that CSG does not reliably correlate with downstream link-prediction performance (MRR and related metrics). In short: CSG, as currently used, is fragile for KG link-prediction evaluation and we recommend caution when using it to compare datasets or predict model performance. (arXiv)
Where it appeared
Accepted as a poster in the Affinity Event — 4th MusIML workshop co-located with ICML 2025. The preprint is available on arXiv. (ICML)
Key findings
- CSG is highly sensitive to the nearest-neighbour parameter (K). Small changes to (K) can dramatically change CSG values — which means CSG does not inherently scale with the number of classes as previously claimed. (arXiv)
- Weak correlation with link-prediction performance. CSG values showed weak or no correlation with standard ranking metrics like Mean Reciprocal Rank (MRR) on multiple KG benchmarks. (arXiv)
- Parameter choices matter. Besides (K), the number of Monte-Carlo sampled points per class ((M)) also affects stability — so reproducible use of CSG requires careful, documented settings. (arXiv)
- Recommendation: Don’t CSG for KGs; look at our next work on classifier-agnostic complexity measures that are robust for comparing KG datasets.
How we evaluated CSG
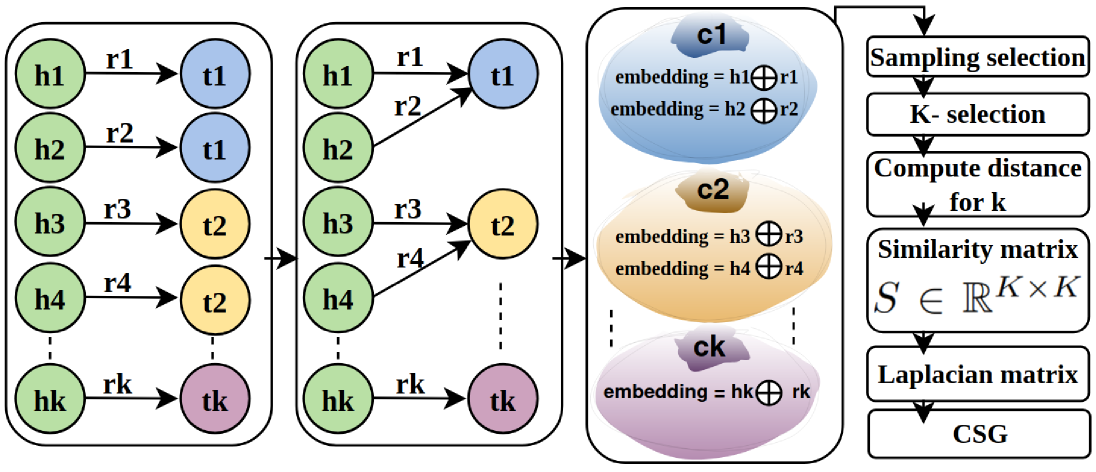
- Design: We transform KG triplets into multi-class representations grouping them by Tail Entities. We then use BERT embeddings for semantic richness, and apply spectral analysis to derive the CSG values.
- Benchmarks used: Standard KG link-prediction datasets (FB15k-237, WN18RR, and others). (arXiv)
- What we varied: the nearest-neighbour parameter (K) (which defines local neighbourhoods in embedding space) and the Monte-Carlo sampling count (M). (arXiv)
- What we measured: how CSG changes with (K) and (M), and whether CSG values track real model performance (MRR & Hits@k) on tail-prediction tasks. (arXiv)
Why this matters
Researchers and practitioners sometimes use dataset complexity scores to decide whether a task is “easy” or “hard,” to compare datasets, or to predict how a model will perform. If a complexity metric is fragile to simple parameter choices and doesn’t correlate with real performance, it can be misleading. Our experiments show that CSG — at least in KG link-prediction settings — gives unstable or unhelpful signals, so relying on it without care risks drawing incorrect conclusions. (arXiv)
Practical advice
- If you use CSG: always report the exact (K) and (M) values you used, test sensitivity across a range of settings, and avoid over-interpreting single CSG numbers. (arXiv)
- Consider complementary diagnostics: empirical learning curves, probe classifiers, and direct correlation checks against the specific model metrics (MRR, Hits@k) you care about.
- For benchmark comparisons: prefer measures and diagnostics that are less dependent on embedding-space hyperparameters.
Links & resources
- Preprint (arXiv): Evaluating Cumulative Spectral Gradient as a Complexity Measure — arXiv:2509.02399. (arXiv)
- ICML pages (Affinity Event / MusIML workshop listing). (ICML)
- ORCID entry for Haji Gul. (ORCID)
Authors
Haji Gul, Abdul Ghani Naim, and Ajaz Ahmad Bhat.